Unstructured data classification is no longer just a process—it’s the foundation of modern data management, transforming scattered, chaotic information into a strategic advantage. As unstructured data surges at an unprecedented pace, businesses must embrace effective classification to achieve visibility, enforce compliance, strengthen security, and extract actionable insights that drive innovation.
By harnessing advanced technologies such as natural language processing, machine learning, and contextual analysis, organizations can address the complexities of unstructured data, optimize storage solutions, and mitigate risks linked to poor data quality and security vulnerabilities. In a world where the adoption of sophisticated classification and storage management tools is becoming the norm, organizations that prioritize unstructured data management today will not only meet the demands of an increasingly complex digital environment but also seize opportunities to innovate, lead, and thrive in the data-driven future.
What is Unstructured Data Classification?
Unstructured Data Classification refers to the process of identifying, categorizing, and organizing unstructured data based on its content, context, and metadata to make it usable, secure, and compliant. Unlike structured data, which fits neatly into databases, unstructured data includes diverse formats such as emails, images, videos, PDFs, documents, and more, making it harder to manage and analyze.
How Does Unstructured Data Classification Work?
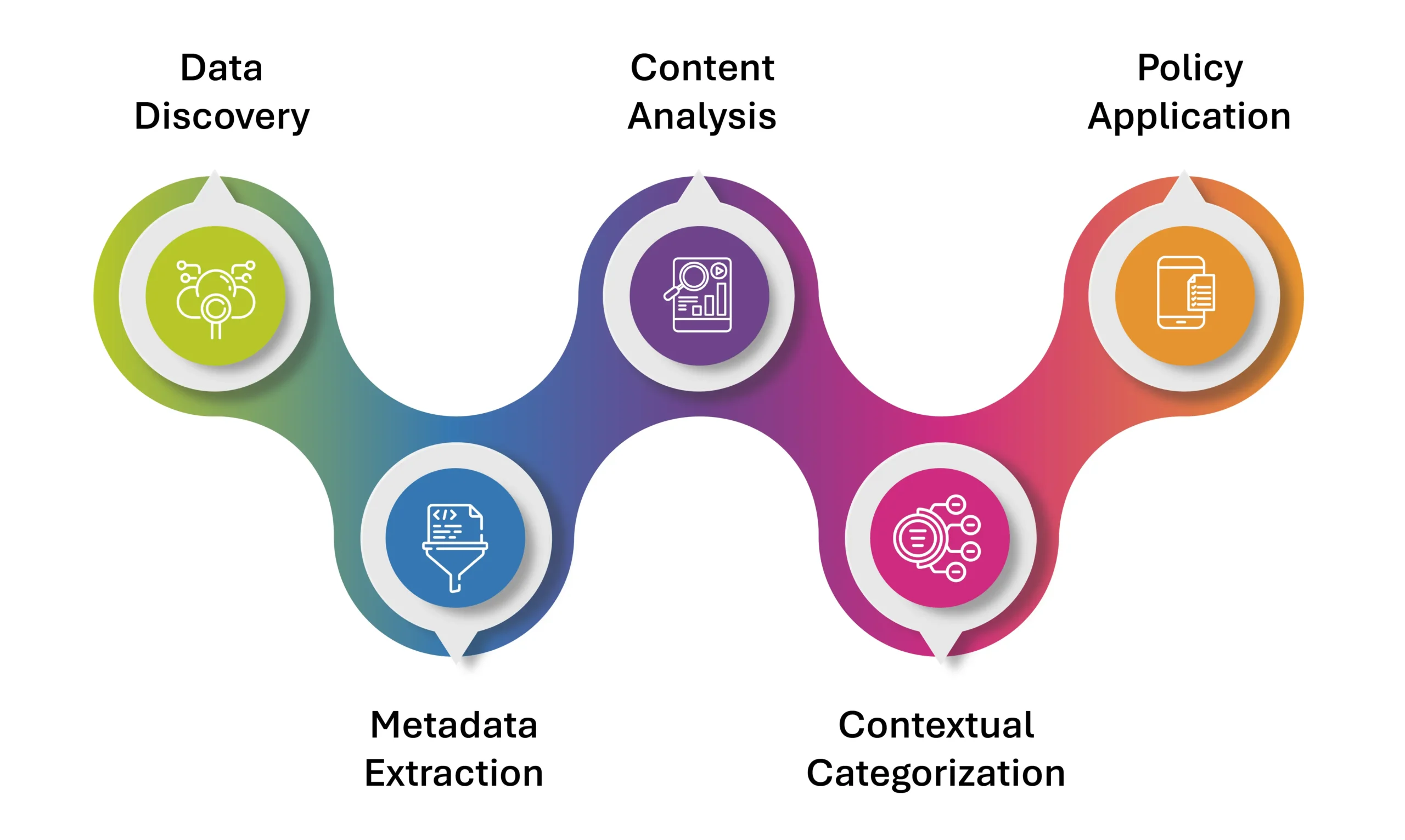
Data Discovery
The process begins by identifying and locating unstructured data across the organization. This data is often scattered in various repositories, including shared drives, cloud storage, local devices, and email systems. Data discovery tools scan these environments to create an inventory of all unstructured data, ensuring visibility into what exists and where it is stored. This step is crucial for understanding the full scope of the data landscape.
Metadata Extraction
Metadata provides key details about files, such as their names, types, sizes, creation dates, and modification histories. Extracting metadata helps categorize data quickly and lays the groundwork for deeper analysis. For example, metadata can be used to identify duplicate files, sort data by age or ownership, and prioritize files for further classification based on their characteristics.
Content Analysis
Beyond metadata, the content within files is analyzed to understand their purpose and context. Advanced technologies like natural language processing (NLP), machine learning, and pattern recognition play a significant role in this step. They can identify specific terms, patterns (such as credit card numbers), or even sentiments within text. This step ensures that data is categorized not just by its appearance but also by its meaning, enhancing accuracy.
Contextual Categorization
Contextual classification involves grouping data based on how it is used, who accesses it, and the purpose it serves. For instance, emails sent by the HR department may be tagged as HR data, while invoices stored in finance folders are labeled as financial data. This categorization aligns data organization with real-world business functions, making it easier to manage and apply relevant policies.
Policy Application
Once data is classified, specific policies are applied to manage it effectively. These policies may include access controls, encryption, or archival rules based on the data’s sensitivity and importance. For example, files classified as containing personally identifiable information (PII) might be encrypted and restricted to authorized personnel only. Automating these policies ensures consistency and reduces the risk of errors or non-compliance.
Industry Insights and Trends:
- Unstructured data is growing at an astounding rate of 55-65 percent annually.
- By 2027, at least 40% of organizations will deploy data storage management solutions for classification, insights, and optimization, up from 15% in early 2023.
- In the United States, poor data quality, often stemming from inadequately managed unstructured data, incurs an annual cost of approximately $3.1 trillion.
Learn More About Managing Unstructured Data:
- Learn about our Unstructured Data Management Software – Zubin
- Schedule a demo with our team
- Read the latest blog: The Chief Information Security Officer’s Playbook for 2025: Trust, Innovation, and Resilience





