In the world of pharmaceuticals, data is king. From clinical trials to regulatory compliance and drug development, every step of the process depends on a vast amount of data. However, with so much data being generated every day, it’s easy for valuable insights to get lost in what’s known as “dark data” or orphan files. In this blog post, we’ll explore how metadata can help optimize your pharmaceutical company’s data management strategy and unlock hidden potential in your dark data. So if you’re ready to learn how to turn chaos into clarity and make the most of your valuable resources – keep reading!
What is dark data? What is an orphan file?
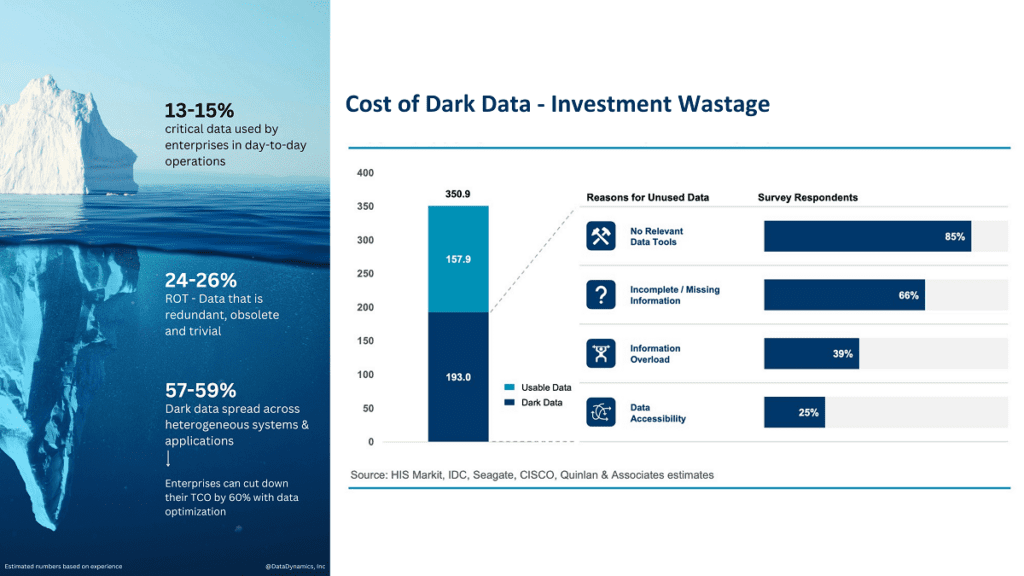
Most organizations have data that they never use. This is called “dark data,” and according to Gartner 60 to 85 percent of unstructured data in shared storage setups is dark. Dark data is a type of unstructured data that is not being used or analyzed. It can be any type of data, such as log files, application data, images, and videos. There are many reasons why dark data exists. One reason is that finding and identifying dark data can be difficult. Another reason is that organizations may not have the resources or expertise to analyze it properly.
However, dark data can be incredibly valuable to organizations. It can contain insights that could help improve business processes or make better decisions. For example, analyzing log files could help identify system issues before they cause problems. If you want to optimize your organization’s data, you need to start by identifying your dark data and understanding what it contains. Only then can you determine whether it’s worth investing the time and resources to analyze it.
An orphan file is a data file not associated with any other files. Orphan files can be created when a user saves a file to a new location without moving or copying the associated files. When these files are no longer needed, they can be deleted.
Overview of the challenges these issues pose to the pharmaceutical industry
The challenges posed by dark data and orphan files are numerous and varied, but all center around these files being difficult to find and manage. This can lead to lost data, higher costs, wasted time and resources, and regulatory compliance issues.
Some of the specific challenges posed by dark data and orphan files include:
- Incomplete data sets: If data is hidden away in hard-to-reach places, it can be difficult or even impossible to find when needed, affecting the accuracy and reliability of research studies and clinical trials. This can lead to incorrect or incomplete conclusions about the efficacy and safety of drugs or treatments, potentially causing significant harm to patients.
- Reduced efficiency: The inability to locate and organize data can lead to reduced efficiency and productivity. Researchers may spend more time searching for data than analyzing it, which can delay drug development and time-to-market. Even when data is eventually found, it may be outdated or irrelevant, leading to further wasted effort. This can hurt the company’s profitability and competitiveness in the market.
- Compliance issues: Dark data and orphan files can pose compliance issues, as pharmaceutical companies are required to maintain accurate and complete records of clinical trials and research studies. Failure to comply with regulatory requirements can result in significant penalties and damage the company’s reputation.
- Missed opportunities: Unanalyzed data can contain valuable insights and information that can be used to develop new drugs and treatments. Without proper analysis, these opportunities may be missed. This can result in lost revenue and a competitive disadvantage in the market.
- Security risks: Dark data and orphan files can also pose risks, as they may contain sensitive patient information or confidential intellectual property. Without proper data management and security protocols, this information may be vulnerable to theft or misuse, leading to legal and financial consequences for the company.
Both dark data and orphan files pose significant challenges to the pharmaceutical industry, as they can impede decision-making, increase the risk of data breaches, and make it difficult to ensure regulatory compliance. To overcome these challenges, pharmaceutical companies must implement robust data management practices that include proper categorization, documentation, and storage of all data, regardless of its type or origin. Additionally, investing in advanced analytics and data mining technologies can help enterprises unlock insights from dark data and make better-informed decisions.
How can metadata analytics help with dark data optimization in the pharmaceutical industry?
Metadata analytics is the process of analyzing ‘data about data’ It is essential to data management, as it provides context and meaning to data sets, making it easier to search, organize, and interpret. Businesses and organizations can gain valuable insights into their data by analyzing metadata, including patterns, trends, and relationships between different data sets. It involves using advanced software tools and machine learning algorithms to extract meaningful information, such as file names, dates, and attributes. This information can be used to improve search functionality, optimize storage, enhance data security, and ensure compliance with regulatory requirements. Metadata analytics can also help businesses better understand their data assets, which can inform decision-making and improve business processes.
When it comes to dark data or orphan files, metadata can help identify where they are located, what they contain, their age, who owns them, and how to utilize them best. For example, you have a large dataset containing clinical trial information. By applying metadata tags, you can easily create a searchable database to find the files you need quickly.
In addition to making your data more accessible and easier to use, metadata can also help reduce storage costs. Since orphan files are often duplicates of existing files within your system, tagging them with metadata can make identifying and deleting them easier.
Metadata analytics is a proven tool for reducing the sprawl of dark data and orphan files in the pharma industry by identifying, categorizing, and optimizing data assets, leading to improved data management. Here are some ways how:
- Categorization and classification of dark data and orphan files: Metadata analytics helps categorize and classify dark data and orphan files by uncovering the hidden value of data and unlocking its full potential for decision-making. This process involves extracting attributes such as file type, date, author, and source and using machine learning algorithms to categorize and classify the data into specific categories. This gives businesses an organized and structured approach to managing their data assets. By grouping similar data files, companies can quickly identify data relevant to their research and development goals, leading to better outcomes. Moreover, categorizing and classifying data assets also help them optimize their data management processes by enabling them to focus on the most valuable data assets and eliminate or archive the others. The result – reduced data storage costs, improved data accuracy and quality, enhanced data security, and reduced risk of data loss. All of this while improving research and development outcomes.
- Optimization of storage: It is a well-known fact that the pharmaceutical industry generates an enormous amount of data. The proliferation of computers, drug manufacturing systems, and automated Internet of Things (IoT) sensors on the factory floor further contributes to this surge, producing vast quantities of digital, machine-generated data every second. The data created since 2003 surpasses that of all previously recorded history. A 2021 study from Tufts CSDD suggests that Phase III clinical trials alone generate an average of 3.6 million data points, which, according to the report, is three times the data collected during late-stage trials ten years ago. Now imagine the cost of storing this data. Estimates suggest that the average cost of storing a single TB of file data is now pegged at $3,351 annually. The total cost for a large-scale pharmaceutical enterprise must be in millions of dollars, if not billions.
Metadata analytics is a valuable tool that enables businesses to optimize storage and reduce costs in the pharmaceutical industry. Analyzing metadata attributes helps enterprises categorize, tag, and index data, making it easier for businesses to identify data assets that are no longer useful or relevant. For instance, metadata analytics can spot data files that have not been accessed or modified for a long time or those that are not linked to any specific application or use case. These data files are classified as dark data and orphan files, respectively. Once identified, businesses can delete, archive, or move these data files to less expensive storage options, freeing up valuable storage space. This can help companies to reduce storage costs while improving the overall performance of their data management systems.
Moreover, metadata analytics also helps businesses optimize storage through a centralized repository of information by enabling them to identify similar data files that can be deduplicated. By doing this, businesses can significantly reduce storage requirements while also improving data accuracy and quality. This can be particularly useful in the pharmaceutical industry, where research and development activities generate large amounts of data. - Facilitates data integration: Metadata analytics is crucial in facilitating data integration in pharma by providing a standardized approach to managing data across different systems, applications, and teams. Metadata refers to information about data, including its structure, format, relationships, and meaning. By capturing and analyzing metadata, pharmaceutical companies can gain insights into how their data is used, identify data quality issues, and improve their data integration processes. Here are some ways it helps facilitate data integration:
- Standardization: Helps standardize data formats, terminologies, and definitions, which is essential for integrating data from multiple sources. Companies can reduce the risk of errors and inconsistencies during data integration by ensuring that all data is organized and labeled consistently.
- Mapping: Aids mapping data from one system to another are essential when integrating data from different sources. By understanding the relationships between various data elements, companies can ensure that data is correctly matched and integrated across systems.
- Quality Control: Enables identification of data quality issues, such as missing data, incomplete data, or inconsistent data. By monitoring metadata, companies can quickly identify issues and take corrective action to ensure data is accurate, complete, and consistent across different systems.
- Collaboration: Empowers teams to work more efficiently by providing a shared understanding of data across different departments and units. By providing a common language and framework for data management, companies can improve collaboration and reduce the risk of miscommunication and errors.
- Improved data security: With the increasing prevalence of cyber attacks, data breaches, and data theft, data security is a top priority for pharmaceutical companies. Metadata analytics can help improve data security by providing insights into the structure, format, and relationships between different data elements. By understanding the metadata associated with each data element, companies can better protect their data from unauthorized access, modification, or deletion. One way metadata analytics improves data security is by identifying sensitive data elements and classifying them according to their level of sensitivity. Companies can apply different levels of security controls to each component, depending on its sensitivity, to ensure the most sensitive data is protected with the highest security controls.
Additionally, it can detect anomalies in data access patterns, which can be indicators of unauthorized access. Suspicious patterns, such as unusual access times, unusual access frequencies, or access from unusual locations, can be identified, and corrective action can be taken to prevent data breaches. Lastly, metadata analytics can identify vulnerabilities in data storage and transmission, such as insecure data storage or transmission protocols. Appropriate security controls, such as encryption or access controls, can be applied to address these vulnerabilities. - Robust compliance: In an industry that is heavily regulated, pharmaceutical enterprises must ensure that they comply with various laws, regulations, and standards. Metadata analytics can help in compliance in several ways.
- First, it can provide insights into data lineage, essential for regulatory compliance. Data lineage refers to the ability to trace data back to its source and understand how it has been used, processed, and transformed. With metadata analytics, companies can track data lineage to ensure compliance with regulations that require data provenance and auditability.
- Second, metadata analytics can help manage controlled vocabularies, which are important for ensuring consistency and accuracy in data reporting. In the pharmaceutical industry, controlled vocabularies define standard terminologies and classifications for drug products, clinical trials, adverse events, and other data elements. Metadata analytics can help ensure the accuracy and completeness of controlled vocabularies by providing insights into usage patterns, discrepancies, and anomalies.
- Third, metadata analytics can help in data governance, which is crucial for compliance. Data governance refers to the processes, policies, and standards for managing and protecting data assets. With metadata analytics, companies can monitor and enforce data governance policies, such as access controls, data retention, and data quality, to ensure compliance with regulatory requirements.
Case study: Johnson & Johnson
In the pharmaceutical industry, numerous data silos and data sets with different degrees of quality exist. One challenge is to use all this data while ensuring that the data used is of the highest quality.
The case study of Johnson & Johnson shows how important it is to optimize one’s data landscape. Through metadata, Johnson & Johnson reduced their research and development costs by 15%. In addition, they improved the quality of their data overall. In the pharmaceutical industry, data is collected from various sources and stored in multiple systems. This data can be a clinical trial, patient records, research, or marketing. Much of this data is unstructured and difficult to access.
Johnson & Johnson has successfully managed this data using a metadata management system. This system allows them to categorize and structure their data, making it more accessible and easier to use. As a result, they have improved their decision-making process and sped up Research & Development.
This case study is just one example of how metadata can improve the quality and efficiency of data in the pharmaceutical industry. If your company is not using metadata today, now is the time to start!
Metadata analytics is a crucial aspect of data analysis that helps pharmaceutical and healthcare organizations extract valuable insights from their data. Organizations can better understand the relationships between data elements, identify patterns and trends, and improve the accuracy of their data analysis. Furthermore, metadata analytics can help organizations with data governance and security by providing a clear view of how data is being used, by whom, and for what purpose. This allows organizations to make informed decisions about their data management practices, ensuring their data is secure, reliable, and easy to use. Overall, metadata analytics is essential for organizations looking to gain a competitive edge by leveraging their data to drive business success and create an efficient & cost-effective data ecosystem.
Data Dynamics’ award-winning analytics suite uses artificial intelligence and machine learning technologies to help enterprises gain critical and accurate insights into unstructured file metadata for accurate PII/PHI/sensitive data discovery, storage visibility, and infrastructure optimization. By facilitating data alignment and refinement, we enable our customers to transform data from existing in a stored state into a business asset. The platform is trusted by 28 Fortune 100 companies and has a proven track record of delivering tangible business outcomes.
We recently helped one of the world’s top 5 integrated healthcare services companies save $7.5 MN in annual TCO by implementing intelligent data lifecycle management for dark data. Read the case study here.
To learn more about Data Dynamics’ metadata software, please visit – https://www.datadynamicsinc.com/analytics/ or contact us at solutions@datdyn.com or call us at (713)-491-4298 or +44-(20)-45520800.





