In today’s digital era, data is the new gold. According to Techjury, the current estimate of data generated every day stands at 1.145 trillion MB. Businesses globally have a mammoth task of storing this vast amount of data which can be a valuable asset if managed efficiently. However, managing this immense amount of information can be quite expensive for businesses, especially when it comes to running data centers. That’s why optimizing your data center through efficient management practices has become more important than ever before in reducing overall operational costs. In this blog post, we will explore the benefits of maximizing efficiency by optimizing your data through different strategies that cut down on costs while improving performance and scalability- all without compromising security or reliability!
What is data optimization?
Data optimization is the process of maximizing the value and efficiency of data by refining and improving its quality, accuracy, and accessibility. It is like unleashing the hidden potential of data, transforming it from a mere collection of raw information into a powerful tool that can drive insights and inform decision-making. Imagine a vast treasure trove of data waiting to be unlocked, with every piece of information carefully analyzed, cleansed, and structured to reveal its true meaning and significance. With data optimization, organizations can harness the full potential of their data, gaining a competitive edge, discovering new opportunities, and achieving greater success than ever before.
Now get ready to be blown away by the staggering numbers behind data centers! With over 8,000 data centers worldwide, boasting a colossal capacity of more than 1500 exabytes (that’s a whopping 1 billion gigabytes!), it’s no surprise that they require a tremendous amount of electricity to keep their equipment running smoothly. The United States takes the lead with 33% of data centers, followed by the UK, China, and Canada. And the power consumption? Experts estimate that data storage and transmission in these centers already use up 1% to 1.5% of the world’s electricity. And brace yourself for this – it’s projected to skyrocket to a jaw-dropping 20% of the world’s energy supply by 2025!
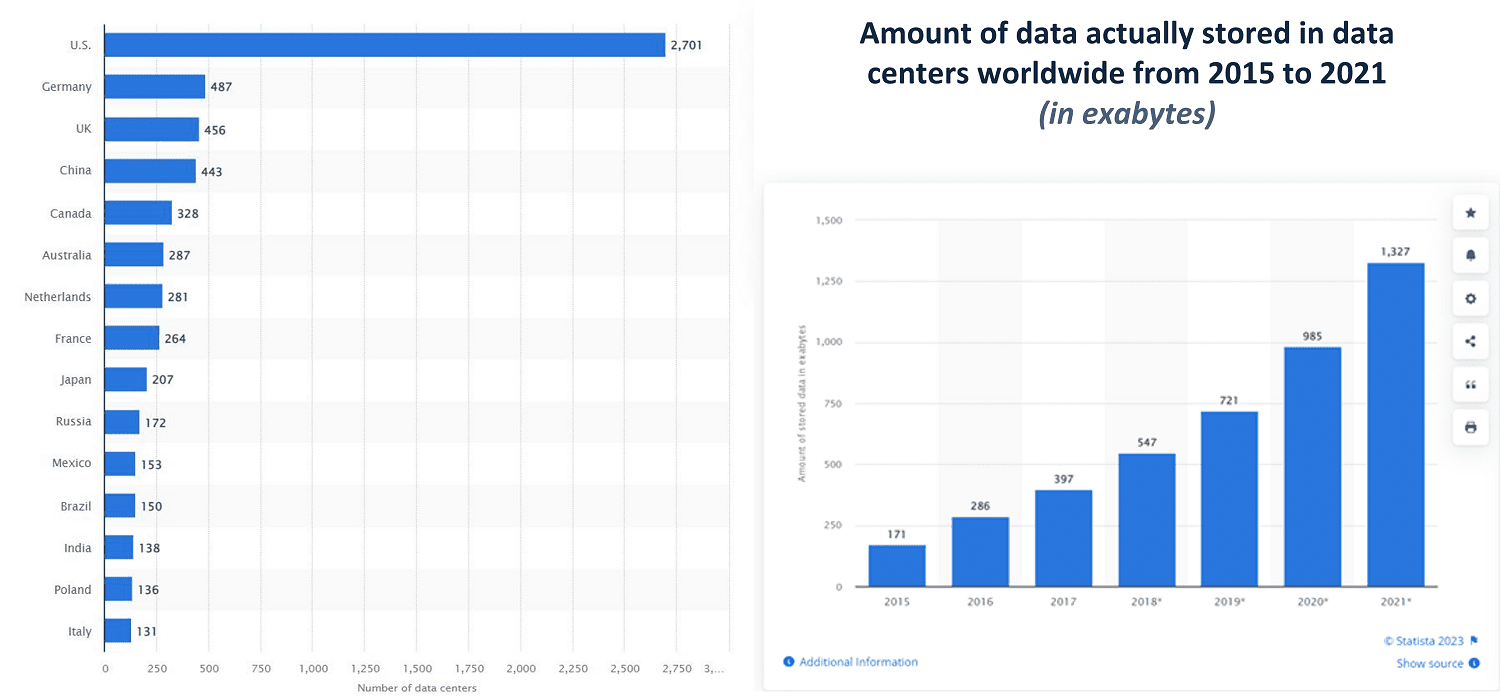
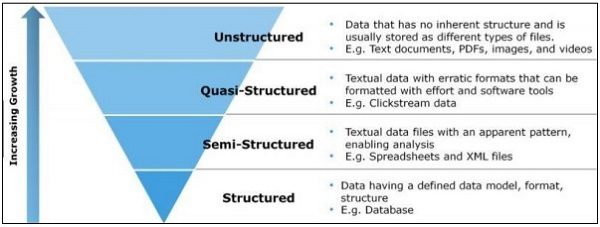
It’s hard to deny the immense potential that data centers hold in terms of transforming markets with breakthrough data insights. However, here’s the shocking reality: a whopping 80% of the data stored in these centers is unstructured, and a staggering 60 to 85 percent of that unstructured data in shared storage setups is considered “dark”. To make matters worse, most companies are only analyzing a mere 1% of their data. It’s no wonder that this data has become more of a liability than an asset! The inability to make sense of this tangle of unstructured data leads to increased costs, and before you know it, organizations are shelling out an annual cost of $10 million to $25 million to maintain their data center. That’s a lot of money to spend when you have no clue what’s in it, let alone how to rationalize your investment.
Uncovering The Impact of Data Sprawl on Data Center Costs
According to forecasts, global spending on these centers is set to soar to a staggering $222 billion in 2023, up from $212 billion in 2022. The Data Centre Cost Index 2022 uncovered that the average cost to construct these centers has shot up by a staggering 15% across global markets. This surge in construction costs can be linked to the pandemic, which triggered the need for remote working and increased automation. Additionally, macroeconomic conditions such as global material shortages have also contributed to construction delays and pushed up costs.

The majority of this rising cost is caused due to the influx of data generated on a daily basis. Did you know that a staggering 85 percent of enterprise data is considered ROT – redundant, obsolete, or trivial? That’s right, according to Gartner’s research, most of the data being stored is useless and taking up valuable space and resources. But how did it get to this point? Unfortunately, it’s a combination of ignorance and a lack of time or ability to properly manage it all.
With the exponential growth of data, no one could have predicted the chaos it would cause. So, what can be done? The first step is to implement a robust unstructured data management process to reduce data sprawl and extract valuable insights from the data that enterprises choose to store.
Eight Data Optimization Techniques to Boost Efficiency and Slash Costs
Unstructured data refers to data that doesn’t have a predefined structure or format, such as text, images, audio, and video files. Managing unstructured data can be a challenge because of its complexity, volume, and diversity. Here are some techniques for reducing and optimizing unstructured data sprawls:
- Use metadata: Metadata is data that provides information about other data, such as its format, structure, and context. By using metadata, you can organize and classify unstructured data, making it easier to search, retrieve, and manage.
- Implement a data classification scheme: A data classification scheme is a system for organizing unstructured data based on its content and importance. By classifying unstructured data, you can prioritize it for storage, retention, and disposal, according to its value and relevance to your organization.
- Apply data deduplication: Data deduplication is the process of identifying and eliminating duplicate copies of unstructured data. This can reduce storage costs, improve data quality, and increase the efficiency of data management.
- Use content analytics: Content analytics uses natural language processing (NLP) and machine learning techniques to extract insights from unstructured data, such as sentiment analysis, topic modeling, and entity recognition. This can help you to understand the content and context of unstructured data, and use it to gain insights and make decisions.
- Implement data retention policies: A data retention policy is a set of guidelines for how long unstructured data should be retained, based on legal, regulatory, and business requirements. By implementing data retention policies, you can reduce storage costs and comply with data privacy regulations.
- Use data visualization: Data visualization uses graphical representations to communicate insights and trends in unstructured data. This can help you to identify patterns, anomalies, and opportunities, and use unstructured data to make better decisions.
- Implement data security measures: Unstructured data is often highly sensitive and confidential, and requires robust data security measures to protect it from unauthorized access, theft, or loss. This can include encryption, access controls, backup and disaster recovery procedures, and other measures to ensure the integrity and availability of unstructured data.
- Use hybrid cloud: Tiering unstructured data in the cloud is a common strategy used to manage data more efficiently and cost-effectively. With this approach, data is categorized based on its frequency of access, value, and criticality. The most frequently accessed and important data is stored in high-performance storage tiers, while less frequently accessed and less critical data is moved to lower-cost storage tiers. This allows organizations to optimize their storage costs while ensuring that critical data is readily accessible when needed. Additionally, tiering unstructured data in the cloud enables organizations to take advantage of cloud elasticity, automatically scaling storage resources up or down as needed to meet changing demands. Overall, tiering unstructured data in the cloud can provide significant cost savings and improve data accessibility, making it an essential strategy for managing large and diverse data sets in the cloud.
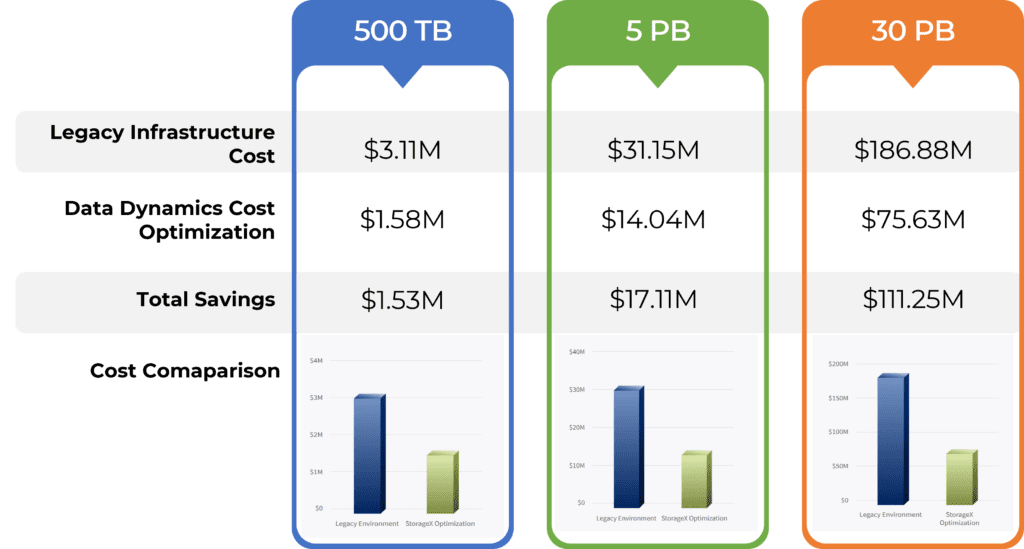
Sounds like a lot, doesn’t it? Fortunately, pre-built data management software specializing in unstructured data can take care of all the complex tasks and deliver a guaranteed reduction in total cost of data ownership costs by over 60%. While a unified data management software is essential, setting it up in-house requires significant investment, time, and may interfere with existing critical projects. That’s why it makes perfect sense for enterprises to use a pre-built data management solution that can deliver accelerated results without the need for in-house setup. By partnering with a trusted provider offering a ready-to-use platform, businesses can customize the solution to meet their specific needs and scale effortlessly. This approach offers a proven and efficient alternative to in-house practices that can help organizations manage their data more effectively and cost-efficiently.
Click here to read more about the Data Dynamics Unstructured Data management platform.
A 5-Step Process to Optimize Your Datasphere
By now, we all agree that data optimization is a crucial process for organizations seeking to maximize the value of their data while minimizing storage costs. Implementing a successful data management and optimization strategy requires a structured approach. Here is a 5 step process to help you implement an effective data management and optimization strategy:
- Define goals and objectives: The first step is to define your goals and objectives for data management and optimization. Identify what you want to achieve with your data, such as improving data quality, reducing storage costs, or increasing business insights. This will help you determine what data you need to optimize, how you should optimize it, and what metrics you should track to measure success.
- Assess your current data situation: Once you have defined your goals, you need to assess your current data situation. This includes identifying all the data sources you have, the types of data you have, and how that data is currently being stored, managed, and analyzed. This step will help you understand the data you need to optimize and identify areas for improvement.
- Develop a data management plan: Based on your goals and assessment, develop a data management plan that outlines the steps you need to take to optimize your data. This plan should include data quality rules, data governance policies, data retention policies, data archiving strategies, and security protocols. It should also identify the software and tools you need to implement your plan.
- Implement the data management plan: With a plan in place, it’s time to start implementing it. This includes establishing data quality rules, implementing data governance policies, setting up data retention policies, archiving data, and securing sensitive data. You should also consider automating some of these processes to improve efficiency.
Case study: 3+ Petabytes of Unstructured Data Analyzed, Cleansed, Tiered, and Archived Using a Lightweight Single Data Management Software for Fortune 50 multinational automotive company
A multinational automotive company, ranked in the Fortune 50, was seeking metadata insights into their file share environment to address several objectives. The company aimed to reduce storage costs through data cleaning, tiering, and archiving while also maximizing the value of their data. To achieve safe and secure data exchange, they planned to develop efficient data access management.
The client faced a challenge with over three petabytes of unstructured data in a NetApp/Isilon File Share Environment. The presence of dark data sprawl in the file share system posed a threat to compliance and invited rogue agents. Furthermore, the unoptimized unstructured data in the infrastructure increased storage costs. A lack of information on the data’s storage locations and organization made it challenging to establish a connection between data and its business value, which resulted in difficulties in ensuring that the right people had access to the relevant data.
The company utilized Data Dynamics’ unified data management platform, an acclaimed software for unstructured data to manage their file share environment’s three petabytes of unstructured data sprawl. The platform facilitated seamless data center migration and consolidation, cloud data migration, and storage optimization, promising 3 times faster speed and 10 times higher productivity.
The customer was able to achieve metadata-driven data management by leveraging various capabilities from Data Dynamics. The ability to perform context analysis made it possible to classify data, thereby facilitating the identification of dark data and enabling the implementation of cost-effective storage options. The solution also allowed for the deployment of dynamic storage scalability based on shifting workloads to optimize operations and storage costs. Data knowledge was used to achieve successful data governance across data silos. Also by identifying sensitive data, the solution provided role-based assessment and privacy controls to eliminate the risks associated with sensitive data. The platform also used the blockchain technology to create an immutable audit trail to monitor data access activities.
The software has been used by more than 300 customers worldwide, including 28 Fortune 100 organizations, and has analyzed and migrated over 400 PBs of data. By using Data Dynamics, the customer could classify, assess, and identify data more effectively, resulting in improved data search, deeper analytics, data tiering and storage optimization.
Click here to download the case study.
Data optimization has certainly proved to be a valuable asset in cutting data center costs and maximizing efficiency. Through the use of analytics tools, virtualization techniques and storage systems, businesses can optimize their data usage to reduce overhead costs while still maintaining performance levels. Not only can this help organizations remain competitive but it can also provide them with greater insight into their operations allowing for more strategic decision-making. Data optimization is here to stay, so embrace it now and reap the rewards!
To know more about how Data Dynamics can help you optimize your datasphere, visit www.datadynamicsinc.com or contact us at solutions@datdyn.com or call us at (713)-491-4298 or +44-(20)-45520800.




