In today’s hyper-digital world, data is everywhere—big, fast, unstructured, and often chaotic. Navigating a global data deluge, where 2.5 quintillion bytes are produced each day, the challenge goes far beyond data storage. The real question is: How do we make sense of it all?
This is where data transformation steps in. This process isn’t just about tidying up; it’s about building a resilient data ecosystem capable of delivering real-time insights and supporting adaptive decision-making.
Building Blocks of Data Transformation
At its core, data transformation is about turning raw data into actionable insights. This process is adaptable, aligning diverse data types with specific business goals. Imagine it as a refining journey—data undergoes cleaning, mapping, and aggregation, ultimately becoming cohesive and purpose-driven to support organizational objectives. Let’s dive in and see what data transformation includes:
1. Data Cleaning and Normalization
Data cleaning involves identifying and rectifying inaccuracies or inconsistencies within the data, often using methods such as deduplication, outlier detection, and validation against predefined rules or standards. Tools like regex and SQL queries are frequently employed for this purpose, while machine learning algorithms can enhance accuracy by learning common data patterns. Normalization then standardizes data across tables and databases by organizing it into a structured, uniform format. Techniques like min-max normalization or z-score standardization can lead to improved data quality and reliability, facilitating smoother data integration and analysis across systems. According to Gartner, poor data quality costs businesses an average of $12.9 million annually, emphasizing the need for automated processes to uphold data integrity continuously.
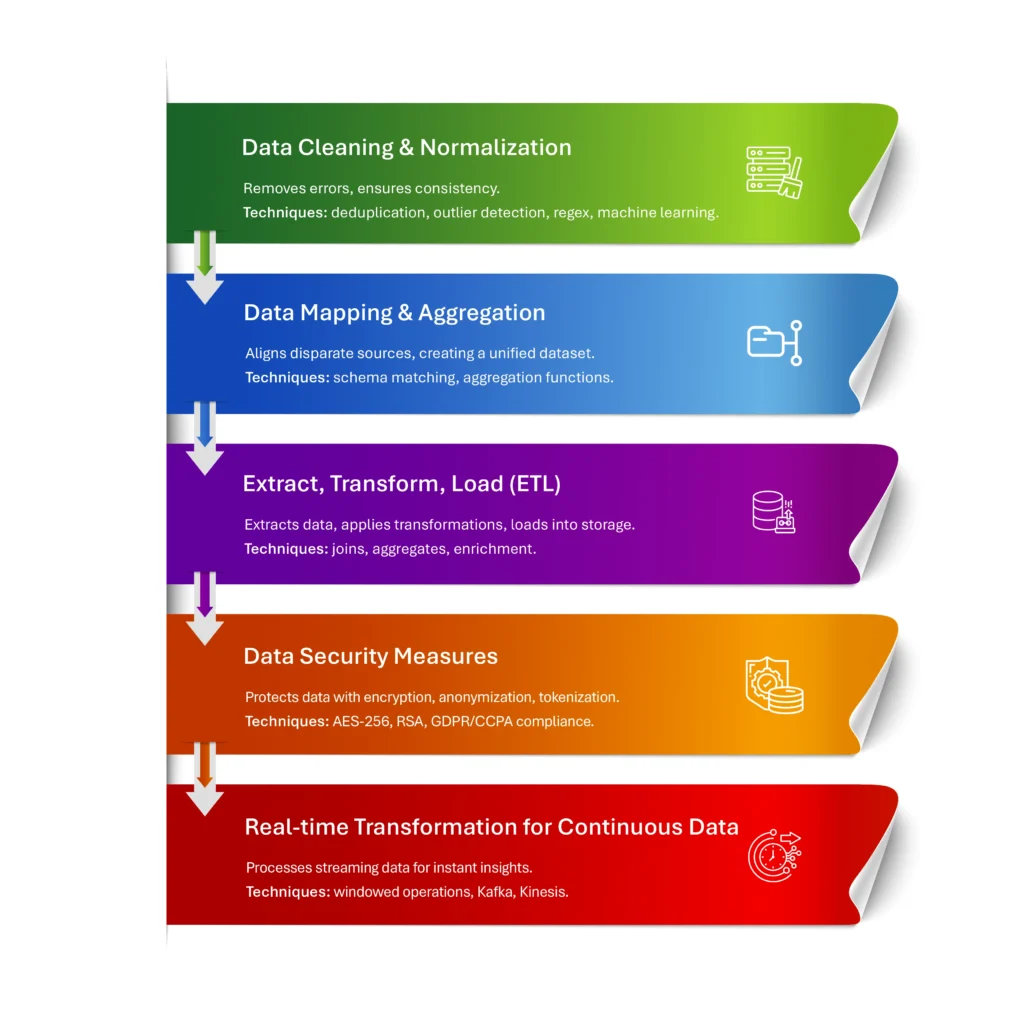
2. Data Mapping and Aggregation
Data rarely “speaks the same language” when it flows in from multiple sources—sales systems, customer support logs, or IoT sensors. Data mapping aligns these disparate sources and establishes transformation rules to convert data from various source fields to target fields. This process may involve schema matching, field-level mapping, and semantic mapping to ensure that disparate datasets align meaningfully. Using techniques like extract, transform, load (ETL) and API-based connectors, mapping tools enable seamless communication between systems, creating a unified data set with a cohesive business view. Aggregation follows by compiling data at various levels (e.g., daily, monthly) using functions like sum, average, or count, simplifying large datasets into actionable, high-level metrics. This method supports comprehensive reporting and analytics, allowing stakeholders to make data-driven decisions quickly without sorting through raw data.
3. Extract, Transform, Load (ETL)
ETL is the backbone of modern data management. The pipelines are structured workflows for data movement and transformation. During the extraction phase, data is pulled from multiple sources, which can include databases, APIs, or file-based sources. The transformation phase often leverages custom scripts or tools (e.g., Apache Spark, Talend) to clean, validate, and standardize data, applying operations like joins, aggregates, and enrichments. Finally, the load phase stores the data in a target location such as a data warehouse or data lake. By enabling data integration across disparate sources, ETL pipelines streamline operations and create a consolidated, reliable data repository, ensuring consistent and accessible information for analytics and reporting.
4. Data Security Measures
Advanced encryption methods, including AES-256 or RSA encryption algorithms, are applied to data at rest and in transit, securing sensitive information against unauthorized access. Anonymization techniques, such as k-anonymity or differential privacy, make it challenging to re-identify individual data points, thereby safeguarding user privacy. Tokenization substitutes sensitive data with non-sensitive tokens, limiting exposure in cases of unauthorized access. Compliance frameworks and data protection laws, such as GDPR and CCPA, mandate these security measures, but beyond compliance, they strengthen customer trust and fortify the business against potential legal ramifications. These data security techniques are integral to robust data management, balancing accessibility with protection.
5. Real-time Transformation for Continuous Data
Real-time transformation is critical for data systems that must process streaming data (e.g., financial transactions, IoT sensor data) instantly. Tools such as Apache Kafka, Apache Flink, or Amazon Kinesis enable real-time data ingestion and processing, providing immediate transformation capabilities. Techniques like windowed operations or stateful processing help detect trends or anomalies on-the-fly, making applications like fraud detection or predictive maintenance possible. The infrastructure needs to handle high data velocities and volumes, ensuring minimal latency and enabling companies to respond dynamically to new information as it arrives. This agility supports sectors that rely on real-time decision-making to stay competitive.
Laying the Groundwork for Data Transformation: Why Data Analytics is the First Essential Step
Think of it like this: in the world we’re in now, data transformation is essential, but jumping in without a solid plan is like setting out on a road trip without a map. That’s where analytics comes into play—it’s not something you tack on later; it’s the first step that shapes everything that follows. Analytics digs into the raw data, picking up on patterns, flagging inconsistencies, and establishing the rules that keep everything on track. It’s like having both the map and the compass, helping you understand the terrain and plan the best route. Starting with analytics means you’re not just transforming data blindly; you’re building a process that’s solid, flexible, and designed to deliver real, actionable insights. Here’s how it plays out:
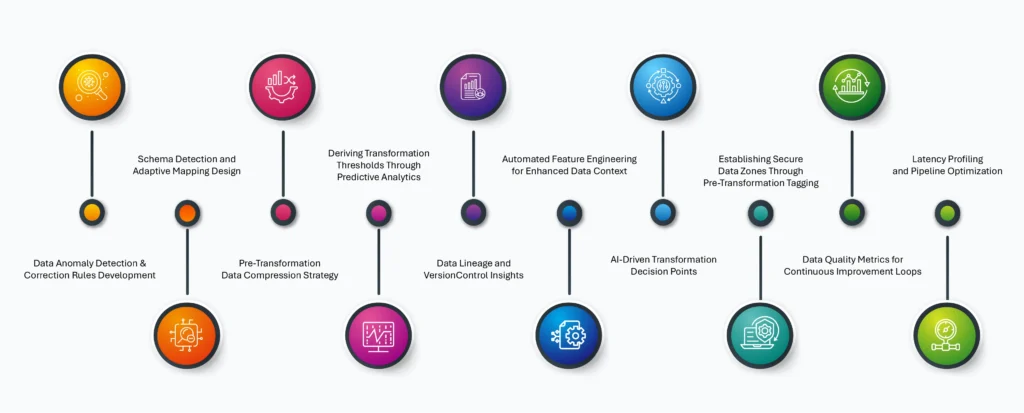
Data Anomaly Detection and Correction Rules Development
The first step in refining data is spotting what doesn’t fit. Advanced analytics, with tools like statistical models and machine learning algorithms (such as isolation forests or clustering techniques), scans large datasets to detect anomalies or outliers. When the system flags an inconsistency—say, missing values or duplicate entries—it’s more than just a diagnostic alert. These insights guide specific correction rules within transformation processes. For instance, if patterns of missing values are detected, the analytics engine can automatically recommend data-cleaning protocols, which minimizes errors and accelerates the entire transformation workflow.
Schema Detection and Adaptive Mapping Design
Data from different sources comes in various shapes and structures, and understanding each schema is crucial for accurate mapping. Here, analytics tools step in, analyzing and identifying data schemas, structures, hierarchies, and relationships across sources. Using schema detection algorithms—like schema matching and fuzzy matching—these tools can automatically recognize field names, data types, and interrelationships. This isn’t just about mapping; it enables adaptive transformation rules that adjust as new data sources appear, saving time and reducing manual adjustments in dynamic environments.
Pre-Transformation Data Compression Strategy
When dealing with large datasets, size matters. Analytics can examine data frequency and distribution to pinpoint which elements are most relevant. With this analysis, a pre-transformation compression strategy can be implemented, reducing dataset size without sacrificing data quality. Techniques such as differential privacy enable anonymization of sensitive data before it even reaches the transformation stage, balancing compliance needs with data utility. This allows high-volume datasets to be efficiently managed without slowing down the transformation process.
Deriving Transformation Thresholds Through Predictive Analytics
Predictive analytics adds another layer of foresight, especially in time-sensitive sectors like finance or healthcare. By analyzing historical data flows, predictive models can forecast peak activity periods, enabling systems to set processing thresholds in advance. This real-time anticipation helps transformation systems avoid bottlenecks by dynamically allocating resources during peak data periods, ensuring scalability and consistent performance even as data volumes fluctuate.
Data Lineage and Version Control Insights
Data lineage is essential for tracing the journey of data through transformation pipelines, especially for compliance and audit needs. Analytics tools with lineage-tracking capabilities allow organizations to see where data originated, what transformations were applied, and where it’s stored. This visibility supports version-controlled transformation pipelines, allowing adjustments based on historical transformations to enhance data accuracy. For instance, if previous transformations reduced data quality, lineage data can inform necessary tweaks to future processes, strengthening data reliability.
Automated Feature Engineering for Enhanced Data Context
Feature engineering in analytics is like adding new dimensions to raw data to enrich its context for transformation. Advanced analytics can automatically generate new variables or attributes, using techniques like polynomial feature generation, cross-product features, or dimensionality reduction methods (like PCA). These added features streamline downstream processes, ensuring that data is primed for aggregation or real-time analytics, and minimizing redundancy by eliminating unnecessary variables.
AI-Driven Transformation Decision Points
Artificial intelligence brings autonomy to transformation processes by dynamically selecting optimal transformation pathways. Through reinforcement learning, AI can evaluate past transformation performance and adaptively choose the most efficient route. If a data source performs well with specific transformations, the AI can autonomously apply this optimized pathway. This approach not only reduces the need for manual oversight but also fine-tunes transformation efficiency based on accumulated data history.
Establishing Secure Data Zones Through Pre-Transformation Tagging
Security remains a cornerstone in data transformation. Pre-transformation tagging, powered by analytics, enables the identification of sensitive data elements and creates “secure zones” within the pipeline. This security tagging ensures that classified or sensitive data is isolated, with selective transformation rules applied to protect it. Techniques like homomorphic encryption or differential privacy tagging safeguard the data, reducing security risks before the transformation process even begins.
Data Quality Metrics for Continuous Improvement Loops
Quality metrics, such as completeness, accuracy, and consistency scores, enable continuous quality monitoring. By establishing pre-transformation baselines, these metrics create feedback loops where any dip in quality triggers remediation protocols. If, for example, completeness scores fall below a threshold, the system can dynamically adjust transformation rules or initiate corrective workflows, ensuring data integrity remains high throughout the transformation lifecycle.
Latency Profiling and Pipeline Optimization
Latency profiling enables a data transformation system to gauge and address bottlenecks, ensuring smoother, faster processing. Analytics tools can measure latency across data sources, allowing the system to allocate processing power more efficiently. High-latency data streams, for example, can be flagged for additional resources, enabling real-time adjustments in the pipeline. By refining pipeline architecture—whether through in-memory or disk-based processing—the transformation process is optimized for speed and reliability.
The Road Ahead
As organizations tackle the intricate demands of data transformation, Zubin by Data Dynamics stands as a powerful ally, bridging the gap between raw, complex datasets and actionable, business-ready insights. This AI-driven self-service data management software is designed to empower organizations in the age of data sovereignty and security and goes beyond traditional transformation. It addresses not only the technical needs of data integration, cleaning, and mapping but also ensures privacy and compliance from the ground up.
With advanced AI-driven analytics, Zubin continuously adapts to the evolving data landscape, automating processes like anomaly detection, data usage recognition, and secure tagging. This enables organizations to handle unstructured data with confidence, streamlining complex workflows and ensuring data quality at every step. By transforming data with precision and resilience, Zubin supports businesses in making agile, data-driven decisions, all while safeguarding their data assets in an increasingly regulated world. To explore more about Zubin and how it could reshape your data transformation strategy visit www.datadynamicsinc.com or get in touch with us at www.datadynamicsinc.com/contact-us/.Data Dynamics, Zubin, AI-driven self-service data management software is designed to empower organizations in the age of data sovereignty and security and goes beyond traditional transformation.





